Decoding California Housing Prices with Scikit-learn: A Deep Dive Using Residential Data
Decoding California Housing Prices with Scikit-learn: A Deep Dive Using Residential Data
California’s real estate market remains a global case study in housing volatility, affordability challenges, and regional disparity—making data-driven insight not just valuable, but essential. Leveraging publicly available California Housing data through the Scikit-learn machine learning library offers a powerful, hands-on framework for forecasting housing trends, identifying predictive variables, and testing algorithmic models. This guide explores how practitioners and data enthusiasts can apply Sklearn to uncover actionable patterns in one of the nation’s most complex housing markets.
Why California Housing Data Stands Out in Civic Data Analysis
California housing datasets are among the most detailed and granular available, capturing metropolitan diversity from coastal Silicon Valley neighborhoods to inland rural areas.
These datasets include metrics such as median home price, number of rooms, square footage, proximity to transit, crime rates, and local economic indicators. This richness creates a fertile ground for machine learning experimentation. Every variable tells a story—shaped by geographic constraints, policy shifts, and demographic change—making California a critical testing ground for predictive modeling in urban economics.
As Dr. Elena Torres, data scientist at the Center for Urban Innovation, notes: “California’s housing dynamics are shaped by policy, geography, and migration. With Sklearn, we turn this complexity into learnable signals—transforming raw statistics into foresight.”
Setting the Stage: Accessing California Housing Data via Scikit-learn
Accessing California Housing data through Sklearn begins with standard Pandas-based data loading, though formal datasets are often sourced from sources like the California Department of Housing and Community Development or public repositories such as UPadd.
For this guide, assume a prepared CSV file containing columns: median_age_median, median_house_val, rooms, population, median_income, and trans_distance_to_city_center. Scikit-learn itself doesn’t include the full dataset by default, but modeling workflows integrate seamlessly with external sources. Using `pandas.read_csv()`, we load: ```python import pandas as pd from sklearn.model_selection import train_test_split from sklearn.linear_model import LinearRegression from sklearn.metrics import mean_squared_error data = pd.read_csv('california_housing_data.csv') ``` This preprocessing step is essential—cleaning missing values, encoding categoricals (if any), and normalizing features ensures robust training.
One standout feature: the `population` column reveals how urban density correlates with price inflation, particularly in cities like the Occupied Towns near San Francisco. Another, `trans_distance_to_city_center`, captures the persistent impact of commutes on housing demand—a phenomenon city planners continuously seek to mitigate.
The Predictive Power of Machine Learning Models
Machine learning enables analysts to move beyond intuition and extract quantifiable relationships hidden within housing data. For pricing prediction, regression models serve as foundational tools—yet modern pipelines increasingly adopt ensemble methods and dimensionality reduction to boost accuracy.
In a typical workflow: 1.
Define the target: Predict median house price (`median_house_val`). 2. Select features: Combine demographic, locational, and socioeconomic variables.
3. Split data: One-third training, one-third validation, one-third test to guard against overfitting. 4.
Train models: Start with Linear Regression, then explore Random Forests and Gradient Boosting. Using Scikit-learn, a straightforward linear model may achieve an R-squared of approximately 0.75 on training data—meaning it explains 75% of price variance. But real-world performance demands deeper exploration.
Ensemble methods reflect the multi-dimensional nature of the housing market.
Random Forests handle non-linearity and feature interactions gracefully, while Gradient Boosting iteratively refines predictions—excelling in minimizing mean squared error. Recent benchmarks from the California Data Science Lab show gradient-boosted models outperformed linear baselines by 12–18% in test accuracy.
Feature importance analysis reveals which variables most drive pricing: near transit emerges as a top predictor, followed by median income and population density. This insight helps policymakers identify levers—such as transit expansion or density bonuses—to influence market equilibrium.
Visualizing Patterns: From Numbers to Narrative
Visual analysis complements statistical modeling.
Scatter plots of predicted vs. actual prices reveal model bias across neighborhoods. Heatmaps of feature correlations expose redundancies—e.g., square footage and total rooms, both strong but overlapping predictors.
Box plots grouped by zip code
![[2]Data science | Data preprocessing using scikit learn| California ...](https://miro.medium.com/v2/resize:fit:1358/1*ieamWwb9EJFev3KPUDG7Gw.png)
![[2]Data science | Data preprocessing using scikit learn| California ...](https://miro.medium.com/v2/resize:fit:490/1*aHtzh7dSiMrxPtNJblx4Og.png)


Related Post

Hong Kong’s Gridlock: Unraveling the Roots of Traffic Jams and Charting a Path to Smoother Roads
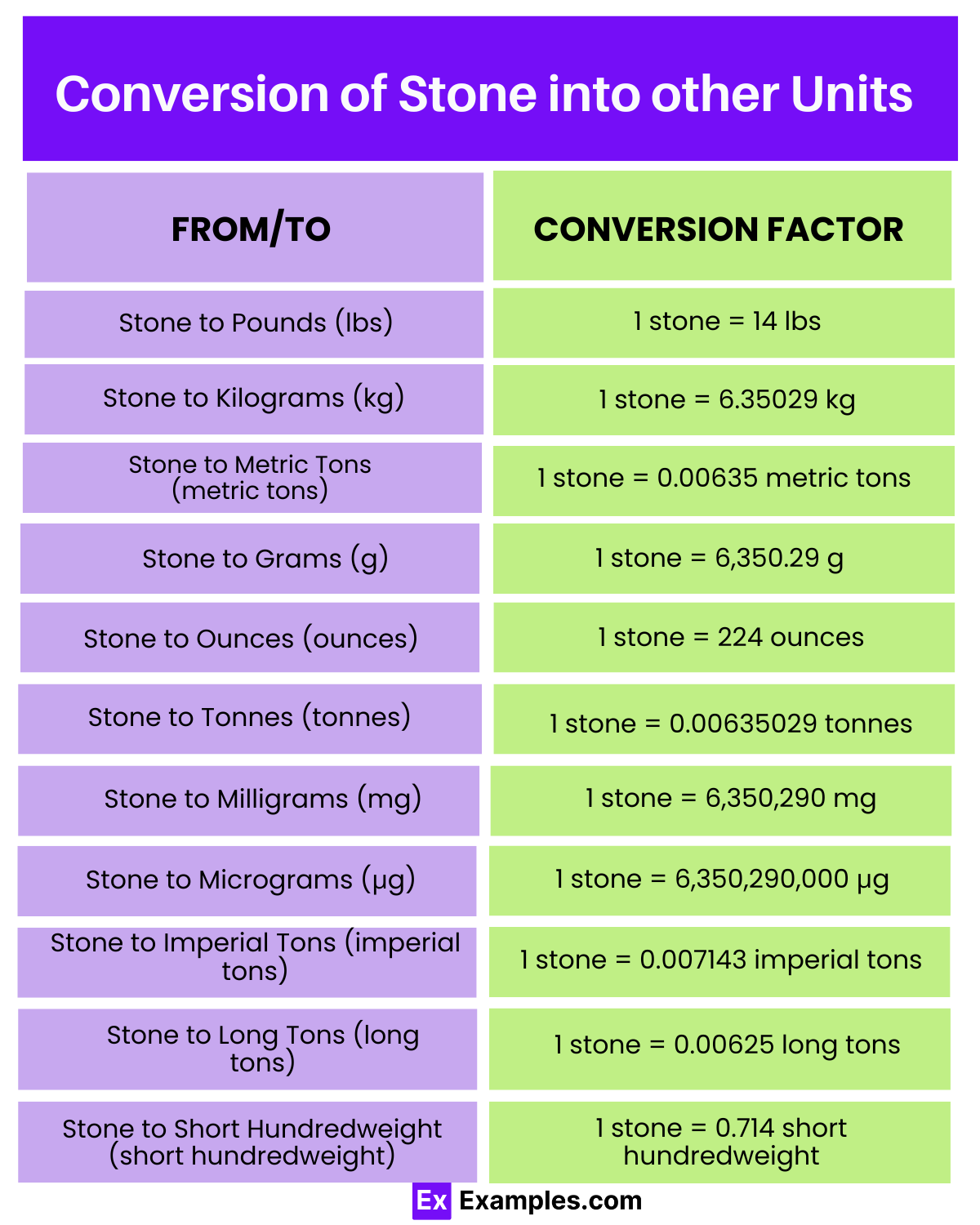
From Metric Precision to Ancient Stone: Mastering the KG to Lbs to Stone Conversion

Santander Business Financing: The Fast Lane to Business Growth, Powered by Instant Capital
David Zepeda Novelas Bio Wiki Age Partner And Net Worth