How to Master取排除特定网页 using Advanced Search Exclusion Tools
How to Master取排除特定网页 using Advanced Search Exclusion Tools
In an era where misinformation spreads swiftly and digital content clutters every corner of the internet, controlling what appears in search results has become a critical necessity. From suppressing outdated news to shielding brand reputation, blocking or excluding specific websites in search engines demands precision and strategy—especially without compromising legitimate results. Using advanced exclusion techniques, users and organizations can fine-tune their information footprint, ensuring only trusted and relevant content surfaces.
This process, often powered by targeted meta-query directives and exclusion syntax, transforms generic search behavior into a disciplined curation of knowledge access.
Modern search platforms provide powerful but often underutilized tools to filter results—among them, the ability to exclude specific websites from appearing in rankings. These exclusion features, typically embedded in advanced search operators, allow users to exclude URLs explicitly, or classify content from known sources as irrelevant.
Far from being a simple “block list,” effective website exclusion operates through nuanced syntax that distinguishes between meta tags, domain boundaries, and content patterns. This precision ensures legitimate links remain visible while de-emphasizing content from undesirable domains.
The Mechanics of Website Exclusion in Search Engineering
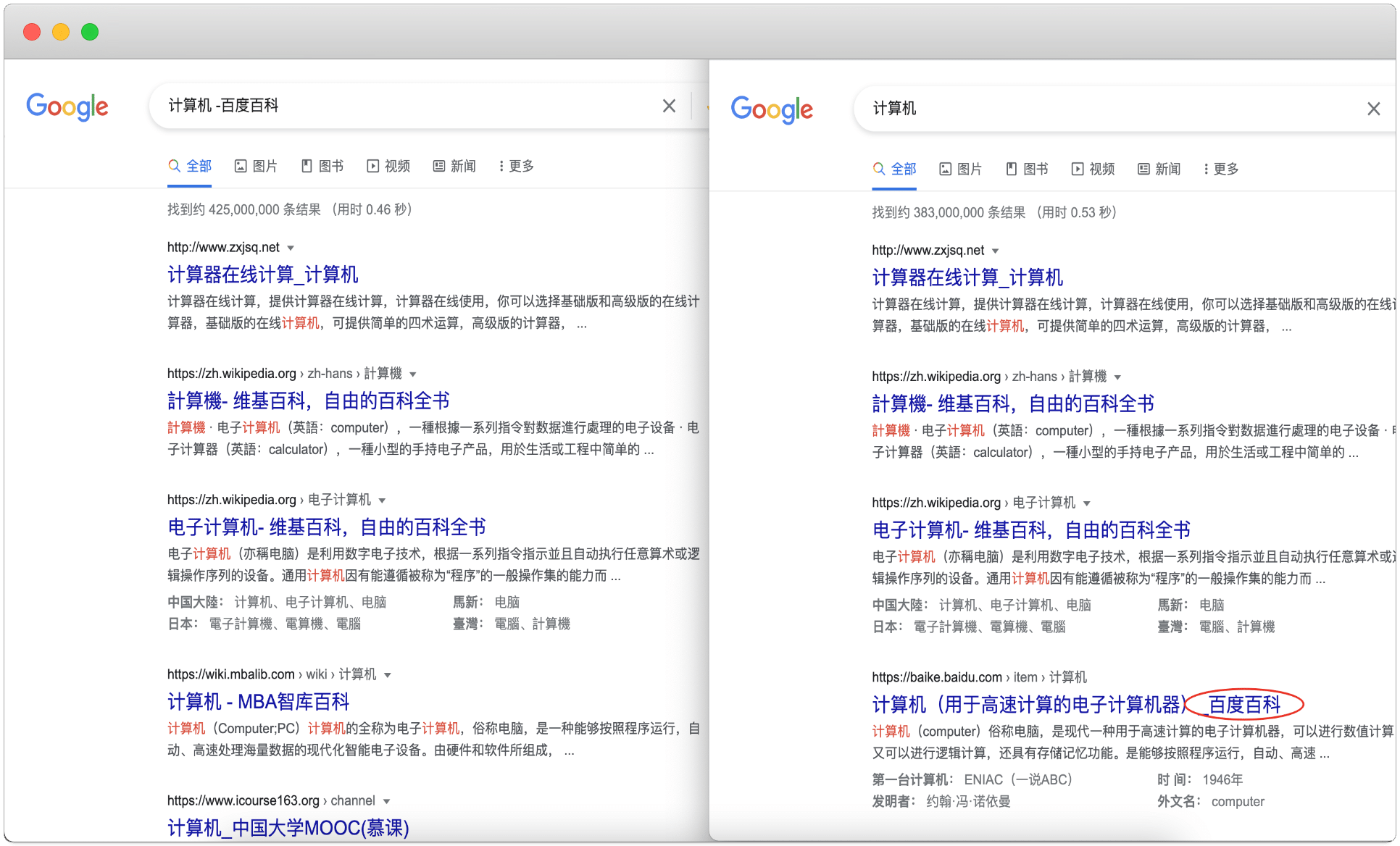
To exclude specific websites from search results, operators vary by search engine but follow recognizable logic. The most widely adopted method is the minus sign operator, used alongside a domain pattern.For example, placing a domain in a hyphenated format—such as Key syntax patterns:
These signals train search engines to treat excluded sites as irrelevant, even when similar terms appear elsewhere. Functionally, exclusion preserves the integrity of search relevance—unlike blanket blacklists that may misremove valid content.
Another layer of sophistication involves excluding only certain types of content from a domain, rather than all pages. Some systems support partial matching or regex-like filters, enabling users to target news articles, forum threads, or download links, while allowing static pages or FAQs to appear. Though not universally available, platforms with granular control—such as enterprise search solutions or advanced personal search tools—offer this precision, enhancing content targeting without oversimplification.
Why Exclude?
Practical Motivations Behind Website Blocking Organizations and individuals adopt exclusion strategies for tangible benefits. For media outlets, suppressing outdated or disputed articles from top search spots protects credibility. A leading environmental NGO, for instance, might exclude archived funding reports from a defunct donor site, ensuring voters see only current, verified content.
- Reputation Management: Brands exclude rival opinions or negative user reviews to maintain control over public perception.
- Content Curation: Educational institutions filter out low-quality or biased blogs from search results, directing users to peer-reviewed sources.
- Legal & Compliance: Organizations block access to jurisdictions with conflicting laws, ensuring data access remains within permitted regions.
The ability to exclude specific domains transforms passive search into active quality assurance.
Real-World Applications and Exclusion Best Practices
Implementing effective website exclusion requires careful planning to avoid unintended consequences. Overly broad blocks risk excluding valuable, legitimate content from authoritative sites.For example, a business directory espousing outdated services may inadvertently suppress only obsolete pages if exclusion syntax targets the wrong domain structure.
Effective exclusion begins with clear rules:
- Audit Target Domains: Use tools like XML sitemaps or crawl analyzers to map which domains contain irrelevant or harmful content.
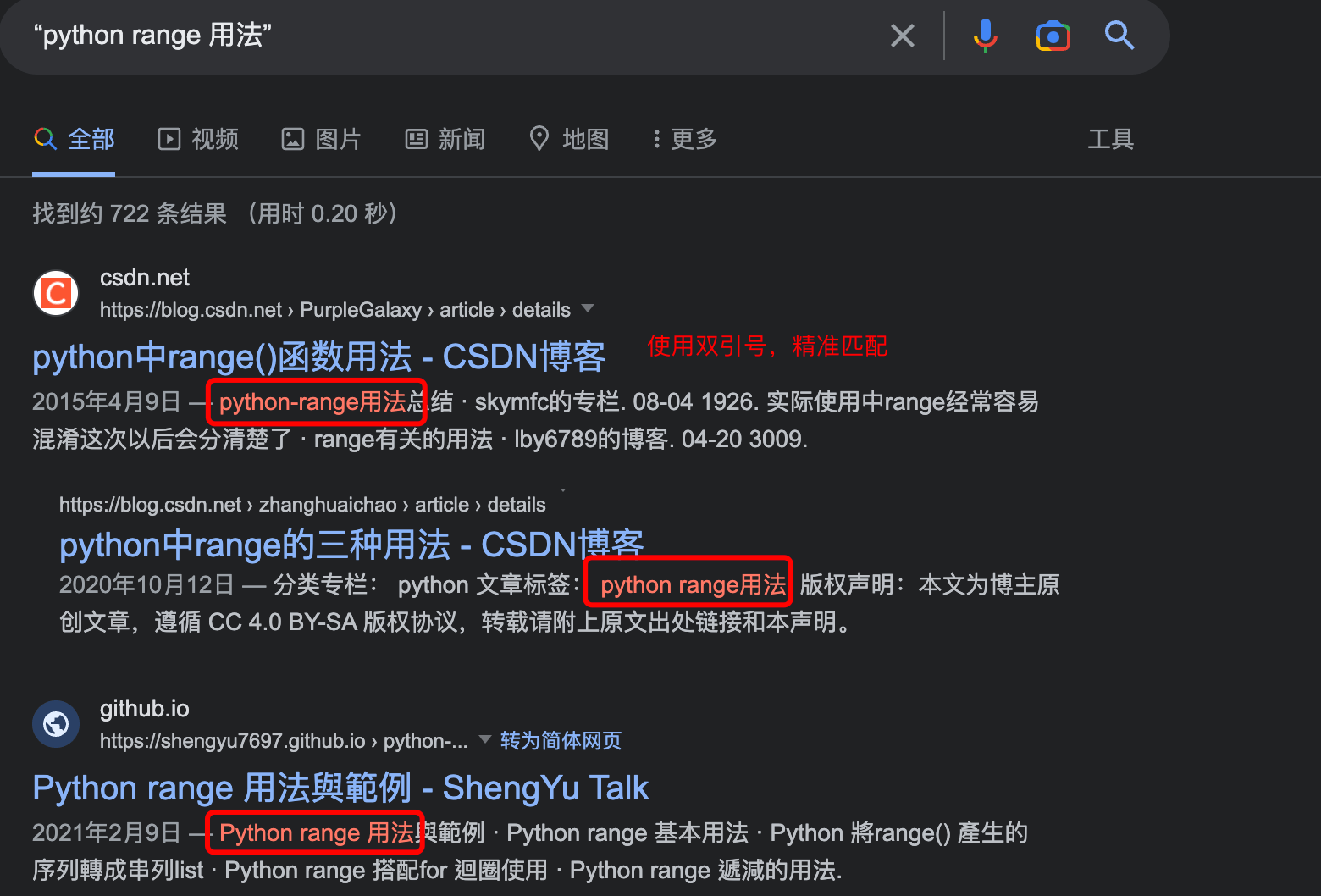
- Apply Precise Syntax: Prefer structured formats (
- Combine with Negative Signals: Pair domain exclusions with “reverse filters” — for instance, excluding <红色内容网站.com> while promoting high-authority links from
.
The Future of Targeted Search Control
As search engines deepen their understanding of context and intent, automated exclusion presets are evolving beyond manual hyperlinks. Emerging AI-driven systems analyze user behavior and content quality to suggest personalized exclusion lists, turning static filtering into adaptive control.Yet, human oversight remains essential—ensuring excluded domains reflect genuine intent, not competitive suppression or bias.
The modern information seeker no longer passively scans results; they shape them. Using exclusions responsibly empowers users to demand clarity, relevance, and trust in digital knowledge. Whether entering a search from corporate, public, or journalistic contexts, mastering exclusion transforms random results into curated insights.
In a world awash with content, the power to exclude defines the quality of what’s found—and why it matters.


Related Post

Chrisean Rock’s Sex Tape: What the Leaked Footage Reveals About a Cultural Flashpoint
Pat McAfee Nominated For Pro Football Hall Of Fame

Kelley King Wdtn Husband: A Union Beyond the Spotlight

OSC, ABPSC, Ananda Live News: Live Update on What’s Shaping the World Today



