Hardware Accelerated GPU Scheduling: Yay Or Nay? The Performance Threshold Engineered
Hardware Accelerated GPU Scheduling: Yay Or Nay? The Performance Threshold Engineered
In the ever-evolving landscape of computational power, hardware-accelerated GPU scheduling stands at a pivotal crossroads—critical to unlocking maximum performance in AI, rendering, scientific computing, and real-time analytics. The question is no longer *if* GPU scheduling should be hardware-accelerated, but *how far*—and whether the trade-offs in flexibility, control, and efficiency justify the shift. This detailed analysis explores the merits and challenges of embracing GPU scheduling acceleration, examining its technical roots, real-world implications, and future trajectory.
Why Hardware-Accelerated GPU Scheduling Matters
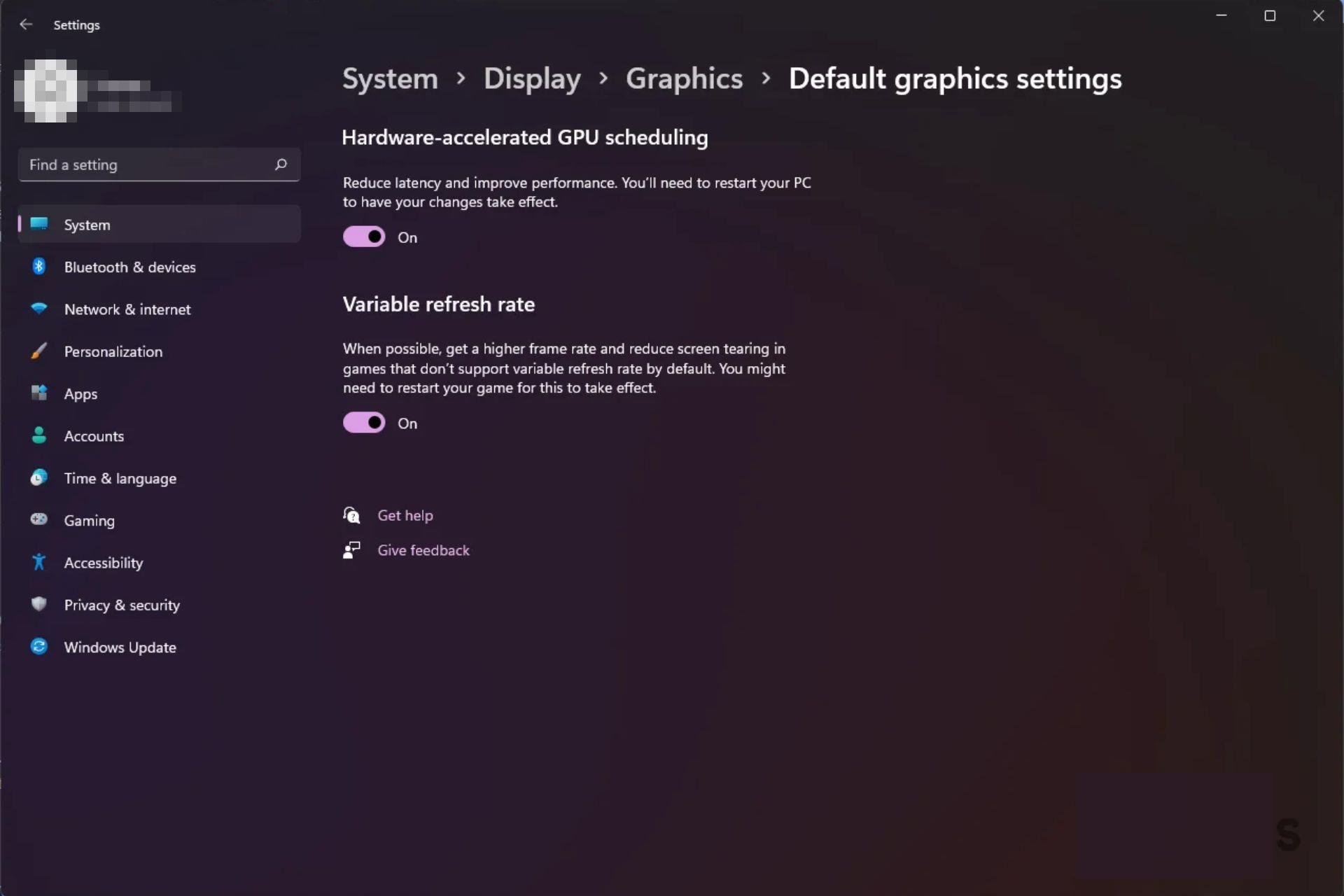
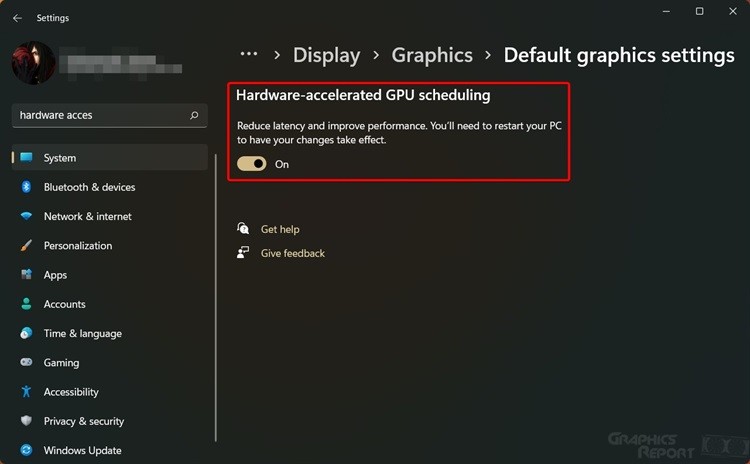
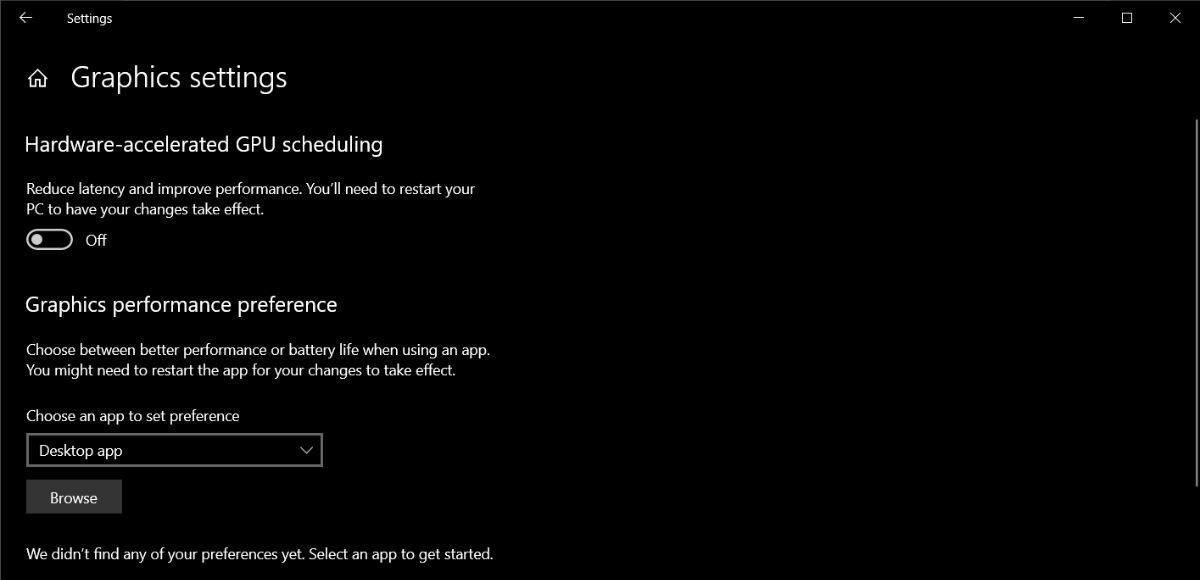
At its core, GPU scheduling governs how computational workloads are dispatched across cores, memory, and execution units. Hardware-accelerated scheduling leverages dedicated controllers embedded within modern GPUs to optimize task distribution dynamically, reducing latency and maximizing throughput. According to Dr.Elena Torres, a leading systems architect at NVIDIA, “GPU scheduling acceleration transforms inert waiting into intelligent coordination—turning parallelism into precision.” By offloading scheduling logic from software to specialized silicon, latency drops and resource utilization spikes, especially in high-throughput applications. 现代GPU利用专用调度控制器,实现任务在核心、内存和执行单元之间的智能分配。这种加速机制显著减少等待时间,提升整体吞吐量,特别是在AI推理和图形渲染场景中,精确调度将并行处理升级为高效执行。
Key Benefits of Hardware-Accelerated Scheduling
- **Latency Reduction:** By minimizing software-induced overhead, hardware scheduling shrinks cycle times between workload initiation and completion. In real-time rendering pipelines, this can translate to smoother frame rates and responsive user experiences.- **Higher Core Utilization:** Efficient task distribution prevents CPU idle time, ensuring GPU cores operate near full capacity even under fragmented workloads. - **Scalability with Complexity:** Large-scale machine learning frameworks and distributed rendering tasks benefit most, as hardware scheduling adapts to workload changes faster than dynamic software approaches. - **Power Efficiency:** Smarter scheduling reduces unnecessary texture and memory accesses, lowering energy use—critical for data centers and mobile platforms alike.
The Trade-Off: Hardware vs. Software Flexibility
While the gains are compelling, open-source frameworks and custom applications often demand granular control over execution order, memory access, and thread prioritization. Hardware-only solutions, designed for speed, impose rigid pipelines that resist rapid reconfiguration.As Dr. James Chen of Stanford’s GPU Research Lab notes, “Scheduling acceleration excels in structured, repetitive workloads—yet opens bottleneck potential when applications demand unpredictable dynamic behavior.” This inflexibility can hinder innovation in adaptive computing environments, where software schedulers offer tailor-made optimization.
Real-World Applications and Performance Gains
In deep learning, hardware-accelerated GPU scheduling dramatically shortens training cycles.Frameworks like TensorFlow and PyTorch integrate scheduler optimizations to prioritize critical tensor operations, cutting training time by up to 25% on high-end GPUs. In game engines, companies such as Epic Games report faster scene updates and reduced input lag by embedding hardware scheduling directly into rendering pipelines. Even in video encoding and CAD software, accelerated scheduling enables smoother playback and responsive editing, even with 8K resolution and complex physics simulations.
Emerging Standards and Industry Support
Modern GPU architectures—from AMD’s RDNA3 and Intel’s Arc to Tesla’s accelerated data center GPUs—now include programmable scheduling interfaces and dedicated control units. These advancements reflect a broader industry shift toward hybrid models: hardware acceleration forms the foundation, while software layers allow deep customization where needed. Open standards like Vulkan’s explicit GPU scheduling extensions are accelerating cross-platform compatibility, empowering developers to harness hardware capabilities without sacrificing portability.Future Outlook: Optimization Not Automation
The trajectory suggests hardware-accelerated GPU scheduling will become the default for mass-produced, performance-critical applications. Yet, the rise of AI-driven, adaptive workloads will keep demand for software-controlled schedulers alive. The future lies not in a binary “yay or nay,” but in intelligent orchestration—where hardware handles routine task orchestration, while software preserves the adaptability needed for cutting-edge, unpredictable use cases.As GPU computing matures, the most successful systems will blend the best of both worlds: hardware scheduling for speed and stability, software flexibility for innovation and precision. Stakeholders must weigh performance at scale against adaptability in niche domains, ensuring that technological choice aligns with real-world needs. In essence, hardware-accelerated GPU scheduling is less a revolution and more a strategic evolution—one that, when applied thoughtfully, unlocks unprecedented computational potential across industries.

Related Post

Zibby Owens Net Worth: Rising Against the Grain in a Competitive Gaming Landscape
Is 4Download Net Safe: Your Ultimate Guide to Secure Software Downloads

Laura Ingram’s Family: Amid Public Scrutiny, Her Ingraham Partnership and Children Remain Steadfast
What Day Did King Von Pass: The Untimely End That Shaped a Rap Legacy



